This Is How Machines Learn! Unsupervised Learning (Part 3)
Our goal with this series is to enable everyone to understand AI phenomena in their daily lives, as well as to actively shape the growing influence of AI on our society. Therefore, we do not consider any technical details or provide an introduction on how to use certain machine learning frameworks. Instead, we focus on explaining the underlying ideas of machine learning which empower everyone to understand and shape the digital world that surrounds us.
If we take a large pile of Lego bricks and ask three children to sort them, the children will most probably create several smaller piles of bricks. They may create these piles based on color or size of the individual brick, even without explicit instructions. This is similar to what unsupervised learning algorithms do.
Underlying Idea
In the case of unsupervised learning, only unlabeled data is given as input. The algorithm then identifies similarities and patterns in this data. The resulting model can be used to group the data or to find outliers, for example.
The steps below describe the activities in the figure.
① For some problems, there is neither labeled data (like in the case of supervised learning, see part 2) nor a way to assess behavior (like for reinforcement learning, see part 4). The available information is instead limited to unlabeled input data: the only form of data available to our robot is a bunch of bricks — without any labels. A real-world application is, for example, the segmentation of customer groups for personalized ads. In this case, the data consists of features such as customer age, previous purchases, or income — but not labels, such as “interested in technology”.
② Unsupervised learning algorithms process the unlabeled data by identifying similarities between features. In the case of our robot, the data consists of the individual bricks and their characteristics, such as the number of corners. The assumption is that the more similar these features are, the more similar the data points are. The same applies to the features of customers: an increase in purchasing behavior, income, age and so on means a higher similarity between two customers.
③ Similar data points are sorted into groups, such as all squares, triangles, etc.. Outliers, such as the circle, are isolated. If we look at customer data, we can also see different groups emerging: For running ads, we now need to inspect the groups and decide which ads are most suitable to which customer group.
The assignment of data points to groups (or “clusters”) based on their features constitutes the model. It is continuously adjusted to each new data point. In contrast to supervised learning, there are no labels for the resulting clusters, only information about which data belongs to a given cluster. Furthermore, we cannot measure the quality of the resulting model objectively, since, in contrast to supervised learning, no statement can be made as to whether an assignment is “right” or “wrong”.
Areas of Application
Unsupervised learning is used when no labeled data is available or where labeling would be highly expensive. Common applications are data clustering, finding anomalies or identifying correlations.

Finding different groups (clusters) within the input data is used in cluster analyses (like in our example with segmenting customers) or in topic modeling. Topic modeling is an approach to automatically identify the underlying topics of text documents. For this purpose, the similarity of text documents is determined based on the words they contain. This results in groups of text documents with the same topic.

The counterpart of clustering is anomaly detection. With anomaly detection, the focus is on finding outliers instead of groups within the data. This is used, for example, in the analysis of (suspicious) network traffic or fraud detection for credit card payments.
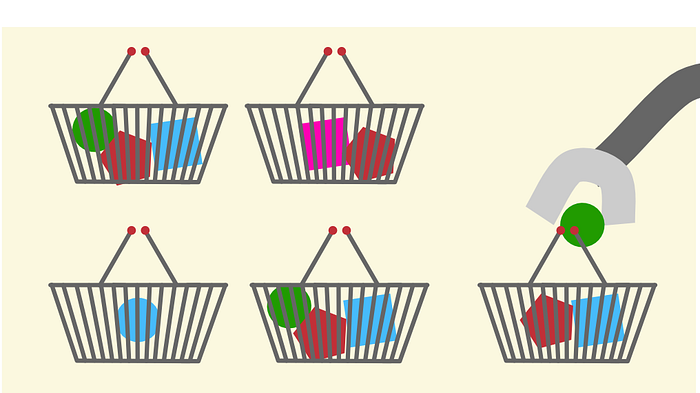
In addition, unsupervised learning algorithms can be used to find previously hidden relationships (association rule learning) in data sets. In the case of online shopping, recommendations are given based on current shopping baskets: Customers who bought expensive watches also bought high-quality whiskey in 70% of cases.
This is it for part 3 of our series. Thank you for reading. If you have any questions, feel free to ask them in the comments.
Click here to go to part 4.
Written by Stefan Seegerer, Tilman Michaeli and Ralf Romeike.
The robot is adapted from https://openclipart.org/detail/191072/blue-robot and licensed under CC0. The article and the derived graphics are licensed under CC-BY.
